”Watashi-tachi wa ningen da!”: A Corpus-Assisted Analysis of a Non-Human Character in the Anime Series From the New World’
Published July 02, 2018
Pages 52-75
https://doi.org/10.21159/nvjs.10.03
© The Japan Foundation, Sydney and Kelvin K. H. Lee, 2018

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.

New Voices
in Japanese Studies
Volume 10
© The Japan Foundation, Sydney, 2018
Abstract
This paper focuses on how social meanings indexed by language use in the real world can be recontextualised in telecinematic texts such as anime to construct and convey different aspects of a character’s identity. In a case study of the science-fiction anime series, From the New World (Shinsekai Yori; 2012—13), the paper analyses three corpora comprised of dialogue from the series in order to shed light on the discursive construction of the non-human character Squealer. A non-human character was selected to minimise the influence of preconceptions about identity. Drawing on Androutsopoulos’s (2012) three-level film analysis framework and Bucholtz and Hall’s (2005) identity framework, the approach incorporates both computerised and manual discourse analysis. The computer-facilitated keyword analysis provides initial insights into the character’s demographic information and speech style, showing the key linguistic features used by the character’s species, and by extension, the focal character. This is complemented by a detailed analysis of dialogue from selected scenes which shows how various aspects of the character’s identity are expressed using different linguistic devices in different contexts. The analysis demonstrates that shifts between the use and non-use of certain linguistic features serve to foreground different aspects of a character’s identity—namely, stances and presentational personae. By integrating corpus linguistic analysis with scene-based analysis drawing on sociolinguistic concepts, the study shows how we can gain insights into telecinematic characters’ identities through language. The paper also highlights issues encountered in applying corpus linguistic methodologies to analysis of Japanese language, which may be of use to future researchers and software developers in this area.
1. INTRODUCTION
This paper examines how social meanings prototypically indexed by language use in the real world are recontextualised in the fictional world of telecinematic texts such as anime to convey various aspects of character identity.1 Using the anime series From the New World [新世界より; 2012—13] as a case study, it explores how sociolinguistic differences are used as a resource for the discursive construction of characters, with analysis centred on the dialogue of a non-human character from the series. The study uses a mixed- method approach facilitated by the use of corpus linguistics, which is an emerging form of investigation involving the computerised analysis of a large volume of selectively compiled linguistic data known as a corpus’. To date, corpus linguistics has been used in a range of linguistic studies focusing on characterisation (e.g., Bednarek 2011, 2012) and other features (e.g., Vignozzi 2016) in (mostly English) telecinematic texts.2 The corpus linguistic approach is slowly growing in a number of Japanese linguistic research areas, including linguistic register (e.g., Fujimura et al. 2012), phonetics and phonology (e.g., Maekawa 2015) and educational linguistics (e.g., Abe 2016; Lee and Nakagawa 2016; Miyata and MacWhinney 2016). However, corpus linguistics seems to be completely unused in any prior studies on discourse in Japanese telecinematic texts such as anime, television dramas and feature films. Based on this shortfall, the key purpose of this paper is to demonstrate how corpus linguistics can be used in a mixed-method (socio)linguistic study to examine the ways in which social meanings indexed by language use in the real world are recontextualised for the purpose of constructing fictional characters.
1.1 Anime and Character Analysis
As a burgeoning popular phenomenon, anime receives a substantial amount of scholarly interest in a number of areas, including gender studies (e.g., Saito 2014), cultural studies (e.g., Fennell et al. 2012), language pedagogy (e.g., Armour and Iida 2014) and fan-translation/fan-subtitling (e.g., Lee 2011). However, despite the extensive interdisciplinary study of anime, linguistic examination of discourse in anime and other Japanese telecinematic texts remains limited. Among the few existing linguistic studies of identity in Japanese telecinematic texts, there are a number of studies that examine character identity (e.g., Hiramoto 2013; Hollis 2014; Toh 2014). Hiramoto (2013), for example, draws on Kinsui’s (2000, 2003) notion of yakuwarigo (役割語; role language’) to examine how pronouns and sentence-final particles are used to construct the imagined identities of the female character archetypes in the anime series Cowboy Bebop [カウボーイビバップ; 1998].3 Hollis (2014), meanwhile, examines how sentence-final particles are used to construct gendered identities in two anime series: Toradora! [とらドラ!; 2008] and Reaching You’ [君に届け; 2011]. Although these studies offer valuable insights into how language (specifically, sentence-final particles and pronouns) is used to construct and convey gendered identities, the focus on gender can be limiting since gender is but one aspect of (character) identity that is discursively constructed.
The identity of both real and fictional beings can be shaped by physical traits such as age, gender or race. However, identity can also be shaped by intangible traits such as one’s personality, stances and affiliations, and by the manner in which one may choose to present oneself. Richardson (2017) observes this phenomenon in dialogue from (primarily American and British) television dramas, which can be seen as parallel with anime due to their shared telecinematic nature:
[T]he speech of any character, at any time, is a performance of that character as a persona,’ with plausible traits of identity (regional/national origins; gender, ethnicity, age—as well as rudeness, sentimentality and other kinds of personality traits). […] The fact that characters’ lines are mostly interactive, i.e., that speech in drama is realised as dialogue, affords a range of possibilities that can be exploited for communicative effects, specifically about the acceptance or otherwise [of] identities and stances that characters project, through a combination of wording and delivery in context.
(Richardson 2017, 40—41)
This study adopts Richardson’s (2017) stance on language use by fictional characters, which regards characters as though they are real’ people by examining them with the identities and traits of real’ people in mind.
Although fictional characters are representative of real’ people to some degree, they do not have to resemble specific humans, nor do they have to be humanoid in form. As Richardson (2010) explains:
Narratives need characters, but there is no requirement that the characters should be human beings. They can be whatever imagination allows and the medium affords, though human nature is always the point of reference.
(130, emphasis in original)
The examination of non-human characters offers a way for researchers to respond to the aforementioned limitations of identity analysis that focuses on gender. In human characters, major social ”categories” such as age, gender and race are easily communicated and interpreted by visual means (Bucholtz and Hall 2005). This results in ”the tendency to bend’ texts so that the analysis fits a pre-determined stance” (Wagner and Lundeen 1998, in Mandala 2011, 6). In contrast, the same social categories are less predictable and more difficult to ascertain in non-human characters, which means that analysis of non- human characters is less likely to be influenced by preconceptions. This study examines the dialogue of one non-human anime character, Squealer ( スクィーラ), to demonstrate how language use can provide insight into character identity. In doing so, it also illustrates that language is a salient tool for identity construction in telecinematic characters, particularly in the absence of easily parsable visual cues.
2. Introducing From the New World
The data for this study consists of the dialogue from all 25 episodes of the science-fiction anime series, From the New World. The series is adapted from a Japanese novel of the same name, written by Yūsuke Kishi (貴志 祐介) and published in 2008 by Kodansha. It was directed by Masashi Ishihama (石浜 真史) and aired in Japan between September 2012 and March 2013. The story is set in Japan, a thousand years in the future (c. 3012), where all humans possess a power known as Juryoku’ which allows them to telekinetically manipulate almost everything in their environment, effectively rendering technology obsolete. The narrative focuses on a human female protagonist, Saki Watanabe (from age 12 to 26 in the main story, 40 in the Epilogue), and her friends, who live in an idyllic village isolated from the outside world. Over time, Saki and her friends come to learn about the true nature of their world, including the dark history that has shaped their current society.
From the New World was selected as the data source as it depicts a world in which a society of a non-human species co-exists and interacts with a human society, thereby allowing analysis of a non-human protagonist acting within a human-centric social and linguistic frame. The non-human species in question is the Bakenezumi’, who appear to be naked mole-rats. The anthropomorphic Bakenezumi live in eusocial colonies, similar to ants or bees, under the control of a queen. They communicate amongst themselves using their own language, which is presented as a mixture of squeaking and grunting vocalisations that are intelligible to neither the viewer nor the human characters in the series. However, each colony has at least one envoy who is fluent in human language and can directly communicate with human officials. These Bakenezumi are able to adeptly use human language (in this case, Japanese) to express aspects of their identity and convey their place in a world dominated by humans.
3. Framework
The mixed-method analysis of Squealer’s dialogue adopted in this paper begins with a quantitative analysis of the character’s linguistic repertoire, based on a computerised keyword analysis. This is supplemented below with a manual analysis of dialogue involving Squealer, Saki and her human male friend Satoru. The discussion of findings about Squealer’s language use draws on Bucholtz and Hall’s (2005) identity framework, described in more detail below.
3.1 A Sociocultural Approach to Identity: The Indexicality Principle
The overarching approach used for the analysis of identity in this study is the framework proposed by Bucholtz and Hall (2005), which synthesises research in several fields to offer a general sociocultural linguistic perspective on identity. In this approach, identity is regarded as an individual subscription to categories of membership that are observed in discourse, rather than as a static and individualistic attribute ascribed by society and internalised by the individual. The strength of this framework is that it views identity as ”intersubjectively rather than individually produced and interactionally emergent rather than assigned in an a priori fashion” (Bucholtz and Hall 2005, 587). Based on this perspective, the framework proposes five principles for analysing ”the social positioning of self and other” (2005, 586). These are ”emergence”, ”positionality”, ”indexicality”, ”relationality” and ”partialness” (2005, 587—607). This study draws primarily on the indexicality principle of the framework, which relates to the use of language to discursively construct identity position. Bucholtz and Hall argue that the indexicality function of language relates strongly to normative language use and draws heavily on linguistic ideologies regarding ”the sorts of speakers who (can or should) produce particular sorts of language” (2005, 594).
It must be noted that Bucholtz and Hall’s (2005) framework is designed for the purpose of analysing and examining the identities of real people. Therefore, by applying this framework, the examination and discussion of language in this study treats fictional character(s) as though they are real’ people who are using language with volition. While the characters may be fictional constructs, it is nonetheless possible to make inferences about ”the broad demographic characteristics the character(s) inhabit” and ”the personality quirks and traits (they) exhibit” (Queen 2015, 155) using this framework.
3.2 Three-Level Framework: Repertoires, Characters and Scenes
The approach used for analysing characterisation is adapted from Androutsopoulos’ (2012) three-level framework for sociolinguistic film analysis, which draws on the concept of repertoire (Gumperz 1964). Linguistic repertoires can be defined as a summary of linguistic codes used by a community (i.e., sociolects) or an individual (i.e., idiolects). When examining telecinematic texts, it is possible to think of the linguistic repertoire of an entire television series or film as the sum of the linguistic codes used by all of the characters in that series or film. Likewise, a character is a summary of how they speak in the film or television series they appear in (Androutsopoulos 2012, 305). Examinations of linguistic repertoire at the level of individual characters can be complemented by examining selected scenes. This allows for more focus on how characters use language in particular contexts and how consistently they use their established linguistic repertoire(s), which can help produce a more holistic picture of the character (Androutsopoulos 2012, 306).
In this study, repertoire analysis is used to profile the salient or dominant speech patterns—that is, language that is the norm or default for these characters in relation to a variety of social and contextual factors—of humans and Bakenezumi. In order to conduct this analysis, corpus linguistic software and the following three electronic corpora are used:
- FNW: a 59,282-word corpus of transcripts for all 25 episodes of From the New World, developed from Japanese subtitle files downloaded from https://kitsunekko.net/. This corpus includes speaker attributions (e.g., Squealer, Saki, Teacher) written in romanised Japanese or English.
- HUMANS: a 49,705-word corpus of dialogue by all human characters, extracted from the FNW corpus and including speaker attributions.
- BAKENEZUMI: a 6,997-word corpus comprising the dialogue of Bakenezumi characters who are capable of human speech (e.g., Squealer, KirÅmaru), extracted from the FNW corpus (excluding speaker attributions).4
By comparing the linguistic markers in the HUMANS and BAKENEZUMI subcorpora, it is possible to determine the most salient linguistic codes used by each species. To achieve this, corpus linguistic methodologies of keyword analysis are used, as detailed below.
3.3 Corpus Linguistic Analysis: A Brief Introduction
Corpus linguistic software allows for a summative analysis of the linguistic repertoire in a film or television series.5 To uncover patterns of language use, this study uses frequency and keyword analysis, which can be achieved using corpus linguistic software. Keyword analysis requires using software to produce lists of words that occur in a corpus, along with their frequencies. The software is then able to compare the frequencies in the wordlist of one corpus against another. This allows the program to generate a list of words or word-forms/clusters that are statistically significant in a node corpus (i.e., the corpus that is being analysed) compared with a reference corpus (i.e., the corpus being used as a point of comparison or comparative norm/standard) (Baker 2006; Scott and Tribble 2006). The resulting words are referred to as keywords due to their unusually high frequency in the node corpus relative to the reference corpus, as determined by their statistical significance.6 The unusually high frequency of a word indicates its keyness or salience in the node corpus (compared with the reference corpus).
Since corpora are encoded electronically, and due also to the large volumes of data involved, computer processing is the most efficient and realistic mode of corpus analysis (Anthony 2009; Baker 2006). However, the use of automated computational analysis is not without problems, especially when analysing a language such as Japanese that has received limited attention from corpus linguists. During this study, three key methodological issues emerged. One is that corpus linguistic software can only recognise words if their boundaries are determined using space—a feature that is rarely used in Japanese writing, if at all (BeneÅ¡ová and Birjukov 2015; Den n.d.). Therefore, to prepare the Japanese-language corpora for analysis, the text first needs to be segmented using segmenting software—here, SegmentAnt (Anthony 2017). SegmentAnt was chosen as it was specifically designed to segment large volumes of Japanese (and Chinese) texts. Despite this, the resulting segmentation was characterised by numerous inconsistencies. Corrections were made to the inconsistent or incorrect segmentations in the FNW corpus, using word and phrase structures outlined in Siegel et al. (2016) as a guide.7
The second issue relates to terminology, which has some implications for clear discussion of the findings. Up until this point, the term word’ has been used when referring to lexical units in written Japanese. However, what the corpus software identifies as words’ consists of lexical words (e.g., です), grammatical particles (such as の and に), affixes (such as —ます and お–) and other bound morphemes.8 This is a result of the way in which the segmentation software parses and then segments the Japanese text, which often involves separating affixes from their word stems. For the sake of consistency and clarity, the term word(s)’ is used to refer to lexical words and grammatical particles, and morpheme(s)’ is used to refer to affixes and bound morphemes.
The third issue is that corpus software creates wordlists based on the form rather than the function or meaning of words and morphemes. This means that the software is unable to distinguish between words and morphemes that are polysemous in nature. For example, de’ (で) is one of the most frequently occurring morphemes in the FNW corpus. However, the software does not distinguish between the many functions of de’, which include its use as a location marker, as an allomorph of the –te’ (—て) suffix, or as the conjunctive variant of the copula. Additionally, de’ can also be considered a marker of honorific language, as the segmenting software separates the super-polite copula degozaru’ (でござる) and its inflections, resulting in de’ and gozaru’ being treated as separate words. For this reason, it is not possible to make conclusions or generalisations about the use of homographic morphemes in the FNW corpus—or by extension, any Japanese-language corpus data that has undergone computerised segmentation—without undertaking further analysis of their meanings and functions. This is a known issue in corpus linguistics that also affects homographs in corpora in other languages. In cases where homographic morphemes or word forms are central to the analysis, it is possible to disambiguate the functions of these morphemes/word forms using part-of-speech tagging (e.g., Weisser 2016, 101—20) and morphological tagging (e.g., Kübler and Zinsmeister 2015, 45—55). In this particular study, de’ was the only affected morpheme salient to the discussion, and it was possible to circumvent the ambiguity by relying on other data; therefore, further analysis was not required.9 However, in the absence of more sophisticated segmenting tools, this issue could prove to be problematic with future corpus-based Japanese-language research where homographic morphemes are more central to the analysis.
4. Findings and Discussion
4.1 Keyword Analysis: Linguistic Repertoires of Humans and Bakenezumi
Keyword analysis was applied to the BAKENEZUMI subcorpus with HUMANS as the reference corpus to determine the key linguistic features in the repertoire of Bakenezumi speech compared with human speech. By analysing linguistic differences based on the socio-demographic traits of each species, it was possible to determine the sociolect or linguistic code allocated to Squealer based on socio-demographic membership—that is, how Squealer does (and should) speak as a Bakenezumi in a world governed by humans.
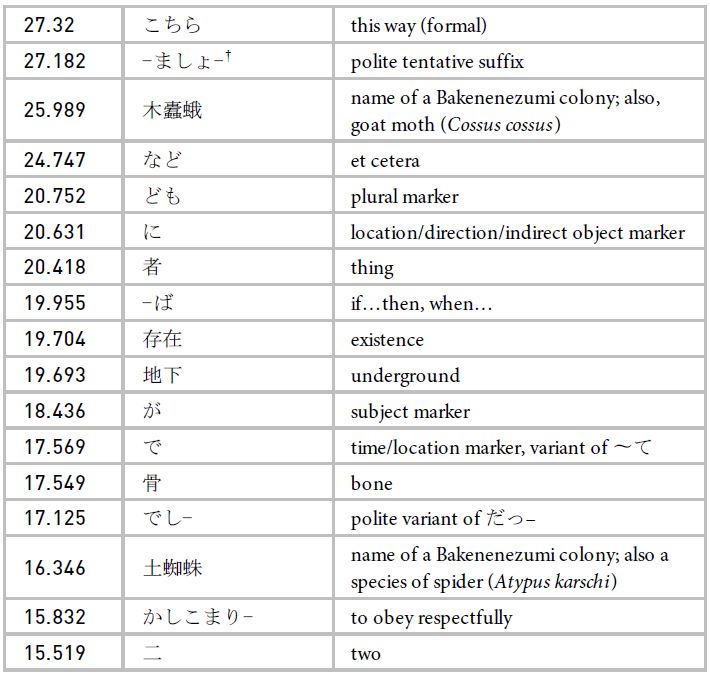
Table 1: Keywords: BAKENEZUMI
Keywords in the BAKENEZUMI subcorpus with a minimum critical/keyness value of 15.13 (p < 0.0001) and a minimum frequency of 5

Notes
* The segmenting software parses gozaru’ as a complete word, but splits all suffixes from the corresponding stems, such that gozaimasu’ (ございます) becomes gozai-’ (ござい—) and -masu’ (—ます), gozatta’ (ござった) becomes goza(t)-’ (ござっ—) and -ta’ (—た).
” The segmenting software also segments out the u’ for all tentative forms, such that mashou’ (ましょう) becomes masho’ (ましょ—) and u’ (—う), deshou’ (でしょう) becomes desho’ (でしょ—) and u’ (—う).
From this keyword analysis (Table 1), several markers of honorific language can be seen, including teineigo (丁寧語; polite language’ or addressee honorific language, e.g., —ます, です, でしょう) and teichōgo (丁重語; courteous language’ or humble language, e.g., おり–, いたし—). There are also a number of non- honorific verbs in their stem form—for example, ‘かしこまり’ (to obey), ‘あり—’ (to be/have) and ‘なり—’ (to become)—which can also flag the presence of addressee honorific language (see Figure 1). Additionally, there are a few markers of bikago (美化語; beautified language’, e.g., お–, ご—), which can also be classified as honorific language in many instances (Jarkey 2015, 196—97). The particle o-’ (お–) can also be a marker of sonkeigo (尊敬語; respectful language’ or subject honorific language), since it is used as one of the affixes for productive subject honorific forms—for example, ‘お書きになる’ (to write’). The relatively high keyness of these linguistic markers suggests that the linguistic repertoire of the Bakenezumi is characterised by honorific language. In the fictional world of the anime (hereafter, the text’), the high frequency of these honorific language markers is attributable to the power imbalance between the humans and the colonies of Bakenezumi to which Squealer belongs.

Figure 1: Concordance of ‘あり–’ and ‘なり–’ in the BAKENEZUMI subcorpus10
Given the relatively low social status of Squealer and the Bakenezumi species in the world of the text, the high frequency of honorific language markers reflects the typical use of honorific language, which is ”to acknowledge and reinforce static social categories in a hierarchical system” (Jarkey 2015, 192). Honorific language is used when referring to or addressing individuals who are perceived as superiors in terms of age, seniority and social status, thereby indexing the hierarchical relationship of interlocutors as well as their relative power distance. This use of honorific language, therefore, indexes the relatively low social status of Bakenezumi in the world of the text.
Among the list of keywords, there are words that are concerned with self-reference—for example, ware ware’ (我々; a formal variant of we’) and waga’ (我が; a formal variant of our’)—or referencing/addressing others, for example kami-sama’ (神様; god(s)’) or ‘jo-ō’ (女王; queen’). The keyness of the two words for referencing others conveys the socially conventional ways of addressing or referencing social superiors, which is influenced by the two power relationships experienced by the Bakenezumi. These terms also index the social position of the Bakenezumi in the fictional world of the text. The use of kami-sama’ reinforces the relationship that the Bakenezumi have with humans. This term of address/reference elevates the status of humans while conveying the relatively low position of the Bakenezumi, reflecting a world order in which humans are dominant. Meanwhile, the use of ‘jo-ō’ as a term of reference creates another rung in the hierarchy between the humans and Bakenezumi, where one Bakenezumi (i.e., the queen) is elevated above the others, further lowering the social status of the general Bakenezumi populace. Overwhelmingly, self-referencing words used by the Bakenezumi are highly formal collective nouns or pronouns used to reference the speaker’s in-group rather than the speaker themselves: for example, wareware’ and watakushidomo’ (わたくしども; humble form of we’). The collectivity of these expressions indexes the Bakenezumi’s strong affiliation with their own in- group, evident in the numerous ways in which they reference their colony and possibly their entire species—for example, waga koronī’ (我がコロニー; our colony’ or our colonies’).
In comparison, the keywords in the HUMANS subcorpus are characterised by markers of plain or casual language (e.g., だ, –てる) and first names (e.g., Saki, Satoru, Mamoru) (see Table 2). These linguistic markers in the repertoire of the humans suggests that the humans regularly engage in conversations with those who are equal or lower in status to them, or those who are highly familiar to them. Additionally, the second-person pronoun anata’ (あなた) appears as a keyword in the HUMANS subcorpus and is generally used as a term of address. Although its use can be either polite or informal depending on context (see Yonezawa 2014), the term seems to be avoided by the Bakenezumi, who prefer terms that explicitly convey power relationships, such as kami- sama’ and jo-ō’. The fact that the humans freely use anata’, either despite or because of its hierarchical ambiguity, suggests that they are often in social contexts where they are not required to clearly recognise superiors, thereby indicating that humans themselves have a relatively superior social standing in the world of the text. Conversely, the fact that anata’ did not emerge as a keyword for the Bakenezumi indicates that ambiguity around the observation of social hierarchy is less permissible, corroborating other indications that their social standing is lower than that of the humans. It should also be noted that the Bakenezumi do use anatagata’ (あなたがた; formal variant of the second-person plural) to address groups of humans. In this context, the addition of the formal humble plural suffix –gata’ (—がた) serves to align the pronoun with the other honorific forms of speech used by the Bakenezumi, supporting the interpretation that the Bakenezumi consciously eschew the singular form due to its hierarchical ambiguity. This further indexes the relatively low social status of Bakenezumi in the world of the text.
Table 2: Keywords: HUMANS
Keywords in the HUMANS subcorpus with a minimum critical/keyness value of 15.13 (p < 0.0001)

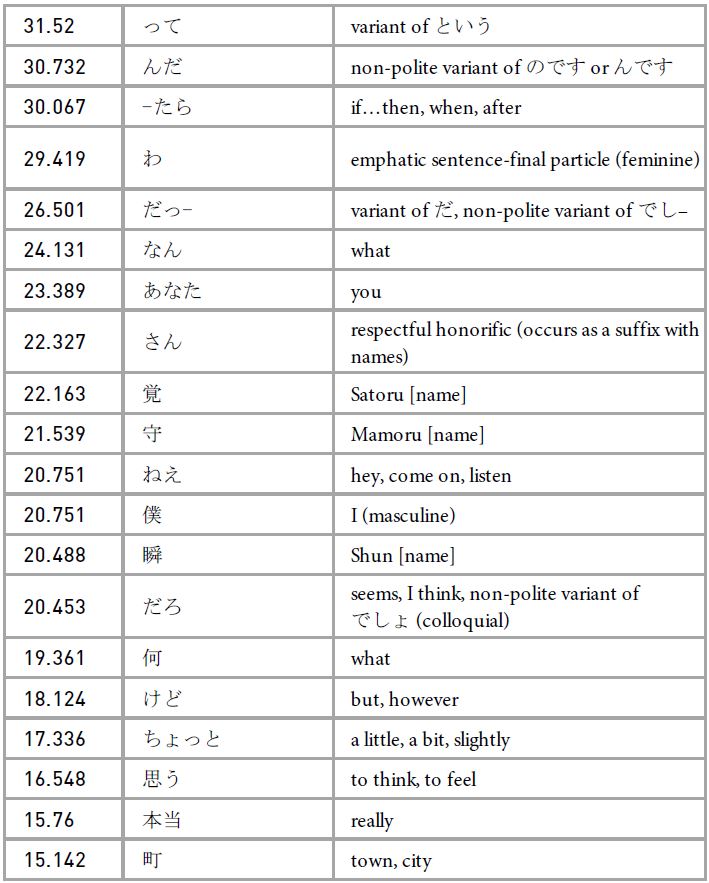
Additionally, there are two types of linguistic markers that emerge as keywords in the linguistic repertoire of the humans, but are either highly infrequent or completely absent from the linguistic repertoire of the Bakenezumi. The first is yo’ (よ), an emphatic sentence-final particle. While yo’ does appear in the speech of Bakenezumi characters, its occurrence is highly infrequent (see Figure 2). Since yo’ is associated with assertions in statements, its infrequency in Bakenezumi speech suggests that the Bakenezumi generally avoid making assertions when communicating with humans, in accordance with social protocols. By extrapolation, the Bakenezumi’s avoidance of assertions can be interpreted as a strategy to appear polite or subservient towards their human interlocutors. Furthermore, Maynard (2001) argues that ”the use and non-use of yo indexes how one wishes to express one’s feelings and one’s selves” (34). By limiting the use of yo’, the Bakenezumi avoid showing their inner personae, which represent their thoughts and beliefs, while maintaining a subservient presentational persona that behaves according to social protocols established by the humans.
![]()
Figure 2: Concordance of よ’ in the BAKENEZUMI subcorpus
The second type of linguistic marker that is highly frequent in the linguistic repertoire of the humans is gendered language, such as the masculine self- reference pronoun boku’ (僕) and the feminine emphatic sentence-final particle wa’ (わ). These markers allow speakers to express and assert their gender identity. The keyword analysis reveals that gendered language is common in the humans’ speech. However, similar linguistic markers do not appear in the speech of the Bakenezumi, who instead rely on gender-neutral, plural self-reference terms such as ware ware’ (我々; formal variant of we’) and watakushidomo’ (わたくしども; humble variant of we’), and generally avoid emphatic sentence-final particles, as discussed previously. This could be related to their strong association with their colonies and their general avoidance of any kind of linguistic markers that would otherwise represent them individually. The relatively high frequency of personal names in human speech compared with Bakenezumi speech also relates to this. Although the Bakenezumi possess their own personal names, these are rarely used by the Bakenezumi beyond the point of self-introduction and are quickly replaced by one of the collective first-person pronouns introduced above.
As this section has shown, a keyword analysis of dialogue can reveal linguistic patterns that are specific to socio-demographic groups in a telecinematic context, which in turn can offer insights into the language use of a focal character. The following section takes an in-depth look at the implications of Squealer’s linguistic code when seen alongside those of other characters who feature in the narrative.
4.2 Character-Based Analysis: Squealer’s Default Linguistic Code
Drawing on the findings of the repertoire analysis, Squealer’s language use is examined in more detail through excerpts from selected scenes in order to establish the character’s idiolect. Here, Bucholtz and Hall’s (2005) framework is used to discuss the indexicality of the use and non-use of certain linguistic items or patterns, as well as the potential indexicality of deviating from the established sociolect. The focus of the discussion is on how the use and non-use of these linguistic features index certain aspects of Squealer’s identity.
As a Bakenezumi, Squealer’s idiolect contains a number of linguistic features that are also present in the Bakenezumi sociolect, such as the markers of honorific language. However, while the use of honorific language indexes Squealer’s relatively low social status in a world governed by humans, the high frequency of markers for honorific language in comparison with their frequency in the dialogue of other Bakenezumi also indexes Squealer’s demeanour (see Table 3). Squealer’s typical speech patterns (until the final episode of the series) are illustrated in Excerpt 1, below.
Table 3: Raw frequencies of honorific language markers (comparing Squealer and other Bakenezumi)
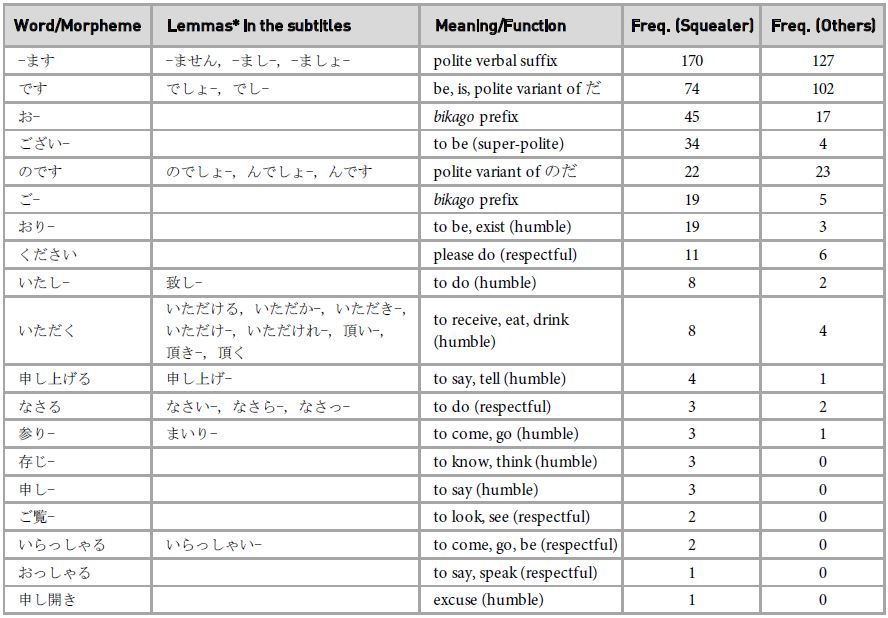
Notes
*Inflectional or orthographical variations of a wordform or morpheme
In this excerpt, Saki (the protagonist) and her friend Satoru become reacquainted with Squealer, whom they have not seen for two years. Here, Squealer uses an elaborate combination of honorific language, including teineigo (addressee honorifics, bolded in lines 1, 3, 6, 7 and 9), sonkeigo (subject honorifics, underlined in line 1), kenjōgo (謙譲語; object honorifics, underlined in line 5) and teichōgo (humble language, underlined in line 9). This combination of multiple honorific language types, along with the term of address kami-sama’ (underlined in lines 3 and 5), communicates a deferential attitude towards the humans as social superiors (i.e., as gods’). In the following excerpts, usage of the different types of honorific language is indicated with corresponding acronyms and the +’ symbol, while the absence of any type of honorific language is indicated by -HON’.
Excerpt (1)11
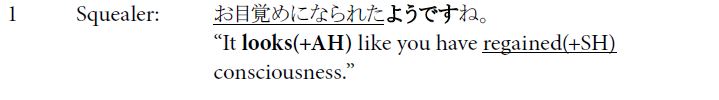

In line 3, Squealer uses the super-polite degozaru’ (in bold), in combination with the honorific suffix -masu’, as degozaimasu’ (でございます). Additionally, Squealer uses a particularly polite grammatical construction (bolded in line 6). Here, the linking suffix -te’ is affixed to the polite suffix -masu’, resulting in the polite conjunctive form (i.e., なりまして) of the word naru’ (なる; to become’)—even though the plain conjunctive natte’ (なって) is acceptable in honorific speech. By using this form, Squealer’s normally high level of honorific language is effectively increased.
Based on this wide variety of honorific language markers, it can be inferred that Squealer’s use of honorific language, in addition to expressing and acknowledging social status or hierarchical relationships (discussed in 4.1), may also relate to Goffman’s (1956) notion of demeanour. Goffman describes demeanour as being ”conveyed through deportment, dress, and bearing” in order ”to express to those in [one’s] immediate presence that [one] is a person of certain desirable or undesirable qualities” (1956, 489). The appropriate use of honorific language can therefore convey a refined demeanour, since it implies strong understanding and mastery of social protocols relating to language use.
Relating to the use of honorific language to express politeness and demeanour, Hasegawa (2006) further relates politeness to the idea of ”prudence” and argues that it is ”linked to social class and socio-political power” (211). Thus, mastery over the use of honorifics is likely to signal membership of a high social class, as well as an overall ”high degree of mental cultivation, elegant refinement, polished manner, and good taste” (Hasegawa 2006, 211). Therefore, while frequent honorific use indexes a low social standing, it also paradoxically indexes cultivation and refinement. Furthermore, Squealer’s interlocutors rarely reciprocate a comparable level of honorific use, resulting in consistent juxtaposition of Squealer’s honorifics with the less polite or refined speech of others. This calls attention to Squealer as possessing a particularly refined demeanour and suggests a degree of social superiority over other Bakenezumi and humans.
As shown here, a character-based analysis can build on a keyword analysis to reveal a focal character’s repeated and salient linguistic patterns (i.e., the character’s idiolect), which gives further insight into aspects of that character. As a Bakenezumi, Squealer uses language patterns strongly associated with the species, which demonstrates the character’s social membership and relative social rank in the fictional world of the text. However, some aspects of the character’s personal traits can be inferred from the overuse of honorific markers—most notably, the apparent desire to present a refined persona. The following section examines a key scene in which Squealer deviates from the established idiolect or character-specific linguistic code, and explores the potential social meanings that this entails.
4.3 Scene-Based Analysis: Speech Style Shifts and Squealer’s Other Persona
The character-based analysis provides a general overview of Squealer’s character and salient characteristics. However, as Bucholtz and Hall point out, identity is not static nor a fixed construct but ”a discursive construct that emerges in interaction” (2005, 587). To address this point, the following analysis of one key scene demonstrates how different aspects of Squealer’s identity emerge in unfolding interactions, and which linguistic forms index these aspects of the character’s identity. Despite the prevalence of honorific language markers in Squealer’s dialogue, it is important to note that these markers are not always used consistently, even within a single conversation or interaction. In the final episode, Squealer begins to use non-honorific language for the first time in the series, which is highly uncharacteristic given the character’s idiolect. This section examines a scene in which Squealer shifts between using and not using honorific language. Drawing excerpts from a conversation between Squealer, Saki and Satoru, this scene-based analysis examines how different aspects of Squealer’s character are foregrounded by adherence to or deviation from the speech patterns established over the preceding episodes.
The conversation from which the following two excerpts derive involves Saki and Satoru visiting Squealer, who has been imprisoned for leadership in a revolt against the human society. In this scene, Saki and Satoru attempt to elicit Squealer’s motives for the revolt, which resulted in a massacre of humans. Excerpt 2 begins following a comment by Squealer about the volatile co-existence of the Bakenezumi and the humans, where the humans would occasionally eliminate large numbers of Bakenezumi. In response, Saki explains that the massacre of Bakenezumi is a heavy punishment which is used as a final resort towards incriminated Bakenezumi and their colonies. She implies that if Squealer had not initiated a revolt, deaths of both humans and the Bakenezumi species could have been avoided.
Excerpt (2)12

Responding to Saki’s comments, Squealer employs the non-polite style to ask the rhetorical question: ‘鶏が先か、卵が先か…’ (Which came first, the chicken or the egg?’; line 4). However, following this, Squealer returns briefly to more typical honorific language and polite speech style (bolded in lines 5, 6 and 7). In the context of a criticism of humans, Squealer shifts into the non-polite style (double-underlined in lines 4, 8 and 9). Based on this, the subservient demeanour indicated by Squealer’s typical use of honorifics can be seen as a façade which breaks down when his true thoughts emerge. This suggests that Squealer is simply acting out a public persona that the humans ascribe to members of the Bakenezumi species.
This is emblematic of the broader conversation from which Excerpt 2 is taken, where Squealer similarly shifts between polite/honorific and non- polite styles. It is likely that these shifts index the switch between a Japanese speaker’s innate’ self and the social persona they choose to present (e.g., Cook 2008; Yamaji 2008). According to Cook, the polite style indexes public self-presentation, whereas the non-polite style foregrounds the ”innate self” (2008, 15). Cook goes on to suggest that these differences in self-presentation further index different social personae. When using the polite style, a speaker is literally or figuratively acting ”on-stage” and is showing their presentational persona or professional self (Cook 2008, 15). On the other hand, a speaker is acting naturally or spontaneously when using the non-polite style, which indexes their private or innate self. The explicitness of the criticisms in Squealer’s non-polite speech aligns with the idea that the non-polite speech style is actually the one that indexes the character’s true persona (i.e., one that resents the humans).
Excerpt 3 below is from the same conversation as Excerpt 2 and forms the latter half of the overall scene. In this excerpt, Squealer is mainly responding to accusations and comments made by Satoru. This example shows the gradual breakdown of Squealer’s established presentational persona, represented by the polite speech style, and the emergence of a previously repressed inner persona, represented by the non-polite or plain speech style.
Excerpt (3)


Here, Squealer speaks primarily using the non-polite or plain style (double- underlined), briefly returning to the polite style in lines 14, 17 and 21 (in bold). These final flashes of politeness can be interpreted as the gradual breakdown of Squealer’s established public persona. In comparison, the increasing use of the plain style marks the gradual shift to dominance of Squealer’s true persona, reflected by the character’s increasingly candid speech. One explanation for this is that Squealer, as a representative of a socially repressed society with much at stake, realises that the only remaining chance for the Bakenezumi is to speak frankly, perhaps in an attempt to gain the humans’ understanding. As such, the fact that Squealer is speaking predominantly in the plain style suggests that the socially repressed inner persona is gradually achieving prominence over the presentational persona at an emotionally charged point in the narrative.
In the scene examined above, uncharacteristic language is used as a device to highlight a character’s inner persona, which in turn is used to candidly reveal thoughts and opinions hitherto hidden from interlocutors. The scene- based analysis demonstrates that (character) identity is not static nor a fixed construct but ”a discursive construct that emerges in interaction” (Bucholtz and Hall 2005, 587). It also demonstrates how a character’s deviation from an established idiolect can allow different aspects of that character’s identity to emerge in unfolding interactions. Taken in its entirety, this section has shown that a corpus-based mixed-method approach to telecinematic texts can offer a highly nuanced level of insight into the identity construction of characters through language.
5. Conclusion
This study has examined how language is used to construct the non-human character Squealer in the anime series, From the New World. Drawing primarily on the notions of the indexicality principle and corpus linguistic methodologies, it shows that salient aspects of a character’s identity can be understood from the character’s established linguistic repertoire, including (but not limited to) strong in-group affiliation, low social status and overall presentation of subserviency. Additionally, the scene-based analysis demonstrates how shifts between use and non-use of certain linguistic features help to foreground different stances and personae. This study demonstrates that insights about the discursive construction of telecinematic characters can be gained by integrating corpus linguistic analysis with scene-based analysis, drawing on sociolinguistic concepts.
A number of issues were encountered when using corpus programs for the segmentation and analysis of Japanese linguistic data in this study, despite the fact that the programs used were designed to be compatible with Japanese linguistic data. In future studies of this nature, meticulous effort will be needed to limit inconsistencies (as with this study, which required manual correction of large volumes of data due to software limitations) or more appropriate software will need to be developed. These issues notwithstanding, this study has demonstrated that corpus linguistics can be used effectively in a mixed-method approach to examine characterisation. In doing so, it has contributed to the emerging area of corpus linguistics in Japanese linguistic research as well as the still under-represented area of Japanese telecinematic discourse studies.
Glossary
bikago (美化語)
lit., beautified language’. Also known as word beautification’. Bikago often involves adding the prefixes お— or ご— to nouns. The main function of these forms is to make words more polite or more aesthetically pleasing (beautiful’), which leads to the speaker being perceived as having an elegant or refined manner of speech.
kenjōgo (謙譲語)
lit., modest language’. Also known as object honorific language’. It is generally used when speakers talk about their own actions or the actions of their in-group members that are related to a person with higher social status (e.g., doing something for someone, helping someone with something). The main function of object honorific language is to show respect to the recipient of the action (i.e., the object of a transitive or ditransitive verb) while humbling the initiator of the action.
sonkeigo (尊敬語)
lit., respectful language’. Also known as subject honorific language’. It is typically used when speaking about the actions of a referent who is older or higher in status.
teineigo (丁寧語)
lit., polite language’. Also known as addressee honorific language’. It is normally used when the speaker considers the addressee psychologically distant, and/or the speaker wishes to honour or show respect to the addressee. This type of honorific language is generally characterised by sentences ending with conjugations of the copula ‘です’ and conjugations of the predicate suffix ‘–ます’.
teichōgo (丁重語)
lit., courteous language’. Also known as humble forms’ or humble language’. These forms neither show explicit respect to the referents nor the addressee, but mainly serve to humble the actions of the speaker.
yakuwarigo (役割語)
lit., role language’. A term coined by Kinsui (2003) which refers to the spoken linguistic (e.g., vocabulary and grammar) and phonetic (e.g., intonation patterns and accents) features that are strongly associated with particular character archetypes.
Anime References
Ishihama, M. [石浜 真史] (dir). Shinsekai Yori [新世界より]. 2012—13; Tokyo: TV Asahi. Television series.
Kaburagi, H. [鏑木 ひろ] (dir). Kimi ni Todoke [君に届け]. 2009—10; Tokyo: NTV. Television series.
Nagai, T. [長井 龍雪] (dir). Toradora! [とらドラ!]. 2008—9; Tokyo: TV Tokyo. Television series.
Watanabe, S. [渡辺 信一郎] (dir). Cowboy Bebop [カウボーイビバップ]. 1998—99; Tokyo: TV Tokyo. Television series.
I am text block. Click edit button to change this text. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
- Telecinematic discourse’ (or telecinematic text’) was coined by Piazza et al. (2011) as an umbrella term for the type of discourse found in films and television series (i.e., fictional, scripted discourse). ↩
- Vignozzi (2016) examines the multimodal semiosis of idioms in Disney films. The study demonstrates that visual representation of idioms in dialogue helps generate audio-visual humour that entertains the audience. Even when they are not used to elicit laughter, these audio-visual puns can help ”make the movie(s) more winsome and captivating” (Vignozzi 2016, 260). ↩
- A definition of yakuwarigo and other Japanese terms can be found in the glossary. ↩
- Since the HUMANS and BAKENEZUMI corpora are derived from a larger corpus (i.e., the FNW corpus), they are referred to as subcorpora (sing., subcorpus’). ↩
- The corpus linguistic software used in this study is AntConc (Anthony 2016). ↩
- To determine statistical significance, the software carries out statistical tests on each word (using the chi- squared or log-likelihood test) and then assigns a p (or probability) value. The lower the p-value, the more likely that the (high) presence of the word is less random and therefore more likely to be due to the author’s/speaker’s choice to use the word more frequently. Since AntConc does not allow adjustment of the p-value, the equivalent keyness (or G²) value is used as a cut-off (see http://ucrel.lancs.ac.uk/llwizard.html for more detail):
95th percentile; 5% level; p < 0.05; critical value = 3.84
99th percentile; 1% level; p < 0.01; critical value = 6.63
99.9th percentile; 0.1% level; p < 0.001; critical value = 10.83
99.99th percentile; 0.01% level; p < 0.0001; critical value = 15.13
A cut-off of 15.13 critical (keyness or G²) value was selected, which equates to p < 0.0001. This limits the list of keywords to those that are the most significant and makes the list more manageable. ↩ - For example, the word kudasai’ (ください; please’), which does not require segmenting, was incorrectly segmented by the software and appeared as kuda sai’ (くだ さい) or ku dasai’ (く ださい). As this example shows, words that did not require segmentation were sometimes segmented by the software. To ensure consistency and the reliability of the data, incorrect segmentations were all manually corrected in the node corpus prior to the extraction of the subcorpora. ↩
- The English translations for these words and morphemes are presented in Tables 1—3. ↩
- The morpheme de’ is only salient to this analysis in its capacity as an honorific marker. In this capacity, it occurs with gozaru’ and its inflections, so it is possible to account for the occurrences of degozaru’ and its inflections using the frequencies for gozaru’ and its inflections only. ↩
- A concordance is a list of all occurrences of particular words or morphemes presented within the context where they are used (Baker 2006, 71). ↩
- In this and the following excerpts, AH refers to addressee honorifics or teineigo, SH refers to subject honorifics or sonkeigo, OH refers to object honorifics or kenjōgo, HL refers to humble language or teichōgo, and SP refers to the super-polite copula. HON refers to honorific language, regardless of the aforementioned subtypes. Both underlined and bold type are used in this excerpt to illustrate the complex honorific usage that characterises Squealer’s dominant speech pattern. English translations of dialogue in all excerpts are adapted from subtitles by Unlimited Translation Works, which can be found at: https://utw.me/scripts/. ↩
- In Excerpts 2 and 3, bold type signifies honorific language, while double-underlined type signifies informal or non-honorific forms. ↩